Building a Scalable Real-Time Data Pipeline with Event Hub, Stream Analytics, Parquet, ADLS, and ADX
In today’s data-driven world, the ability to ingest, process, and analyze data in real-time is crucial for making timely and informed decisions. Azure provides a suite of powerful tools that can help you build a scalable and efficient real-time data pipeline. Combining Azure Event Hub, Stream Analytics, Parquet, Azure Data Lake Storage (ADLS), and Azure Data Explorer (ADX) can create a robust solution for real-time data ingestion and analytics.
Components Overview
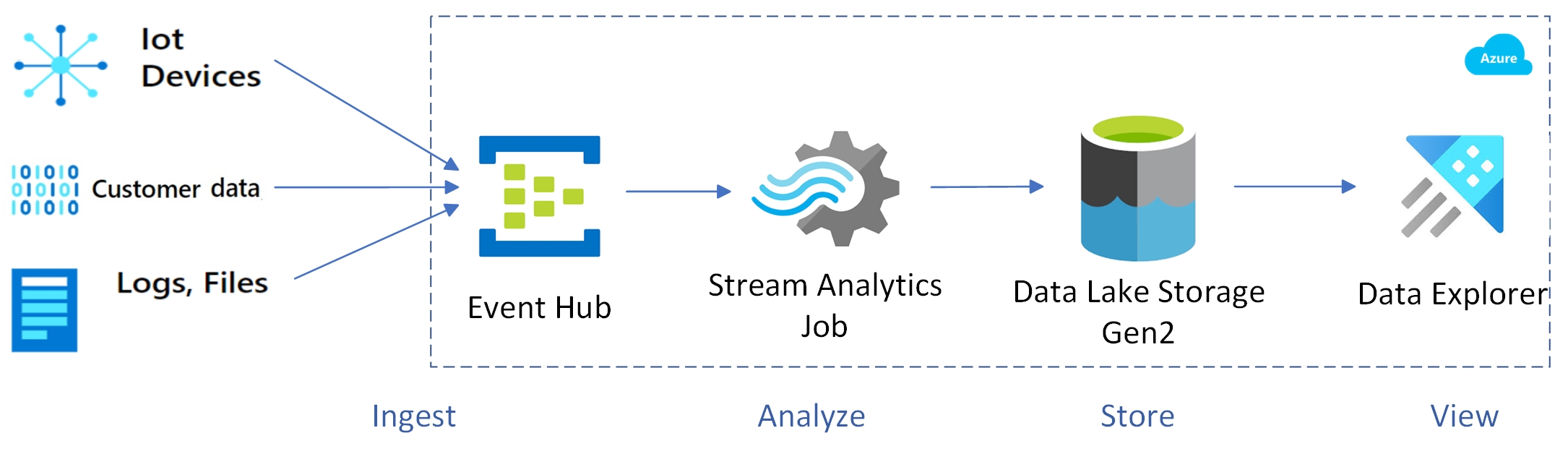 Participating Components
Participating Components
Azure Event Hub
Azure Event Hub is a big data streaming platform and event ingestion service capable of receiving and processing millions of events per second. It acts as the entry point for your real-time data pipeline, capturing data from various sources.
Azure Stream Analytics
Azure Stream Analytics is a fully managed, real-time data stream processing service provided by Microsoft Azure. It allows you to perform real-time analytics on multiple streams of data from sources such as IoT devices, social media, applications, and more. With its SQL-like query language, you can easily filter, aggregate, and transform streaming data to gain valuable insights. Key features of Stream Analytics:
- Real-Time Data Processing: Azure Stream Analytics can process millions of events per second with low latency, enabling data analysis in real-time and quick decision making.
- SQL-Like Query Language: The service uses a SQL-like query language, making it easy for developers and data analysts to write complex queries without needing to learn a new language.
- Integration with Azure Services: Azure Stream Analytics seamlessly integrates with various Azure services, including Azure Event Hubs, Azure IoT Hub, Azure Blob Storage, Azure Data Lake Storage, and Azure SQL Database, making it easy to ingest, process, and store data.
- Scalability: The service is designed to scale automatically based on the volume of incoming data, ensuring that your data processing pipeline can handle varying loads without manual intervention.
- Built-In Machine Learning: Azure Stream Analytics supports built-in machine learning models, allowing you to apply predictive analytics and anomaly detection to your streaming data.
- Reliability and Security: Azure Stream Analytics offers enterprise-grade reliability and security features, including data encryption, role-based access control, and compliance with industry standards.
Parquet Files
Parquet is an open-source, columnar storage file format designed to bring efficiency compared to row-based files like CSV or JSON. It was developed by Cloudera and Twitter and is now an open-source project under the Apache Software Foundation. Key features of Parquet files:
- Columnar Storage: Unlike traditional row-based storage formats, Parquet stores data in columns, which allows for efficient data compression and encoding schemes, reducing storage space.
- Efficient Compression: Parquet supports various compression algorithms (e.g., Snappy, Gzip, LZO), which can significantly reduce the storage footprint of your data. Better compression ratios means less I/O and faster data scans, which can be significant in cloud environments.
- Efficient Query Performance: Columnar storage enables faster read times for analytical queries that only need a subset of columns.
- Schema Evolution: Parquet supports schema evolution, allowing you to add new columns without breaking existing data.
Azure Data Lake Storage (ADLS)
Azure Data Lake Storage is a scalable and secure data lake for high-performance analytics workloads. It is designed to handle large volumes of data, making it ideal for big data analytics. ADLS is part of the Azure Storage suite and comes in two generations: ADLS Gen1 and ADLS Gen2. The latter is the more recent version and offers enhanced features and better integration with other Azure services. Key features of ADLS:
- Scalability: ADLS can scale to exabytes of data, making it suitable for large-scale data analytics.
- Security: It offers enterprise-grade security features, including encryption at rest and in transit, as well as fine-grained access control.
- Integration: Seamlessly integrates with various Azure services like Azure Databricks, Azure Synapse Analytics, and Azure HDInsight.
- Performance: Optimized for high-performance analytics workloads, ensuring fast data retrieval and processing.
- Cost-Effective: Pay-as-you-go pricing model ensures you only pay for what you use.
Azure Data Explorer (ADX)
Azure Data Explorer is a fast and highly scalable data exploration service for log and telemetry data. It allows you to run complex queries on large datasets in near real-time.
Environment Setup
For the purpose of this demo, we will reuse some components from the previous blog post.
Event Producer Code
Clone the console application from the github repo.
After creating the Event Hub, fill in the
EvhConnectionStringandEvhNamein theappsettings.jsonfile.
Event Hub Creation
Follow the steps described in the previous blog post.
ADLS Creation
To create an ADLS Gen2 storage account, in the Azure Portal search for
Storage Accountsselect it and in the upper left corner select+ Create.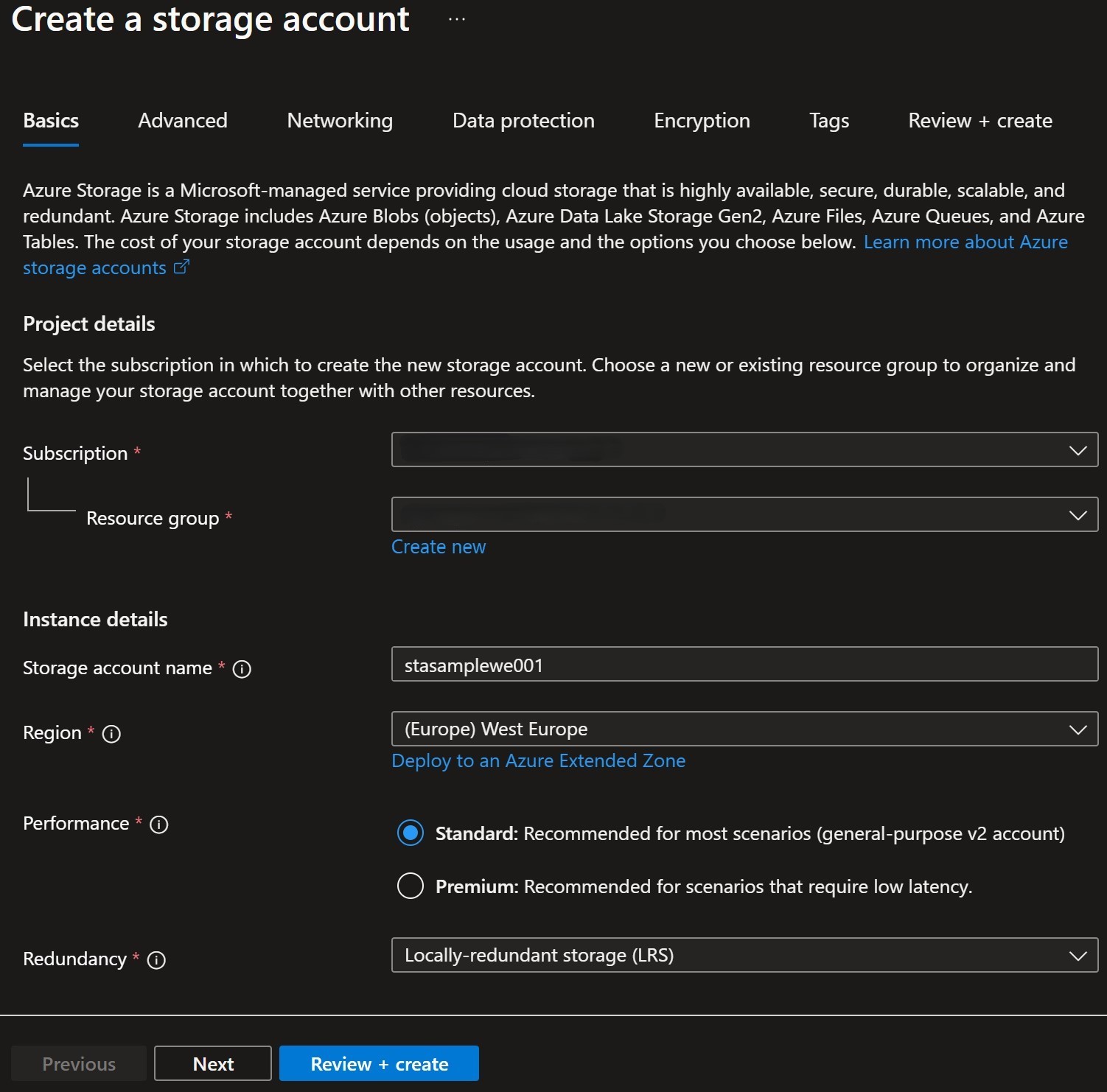 New Storage Account Gen2 creation
New Storage Account Gen2 creationOnce deployment is complete, select it, find
Containersand in the upper left corner select+ Container. For this example we will create two (2) new containers, named “car” and “user”.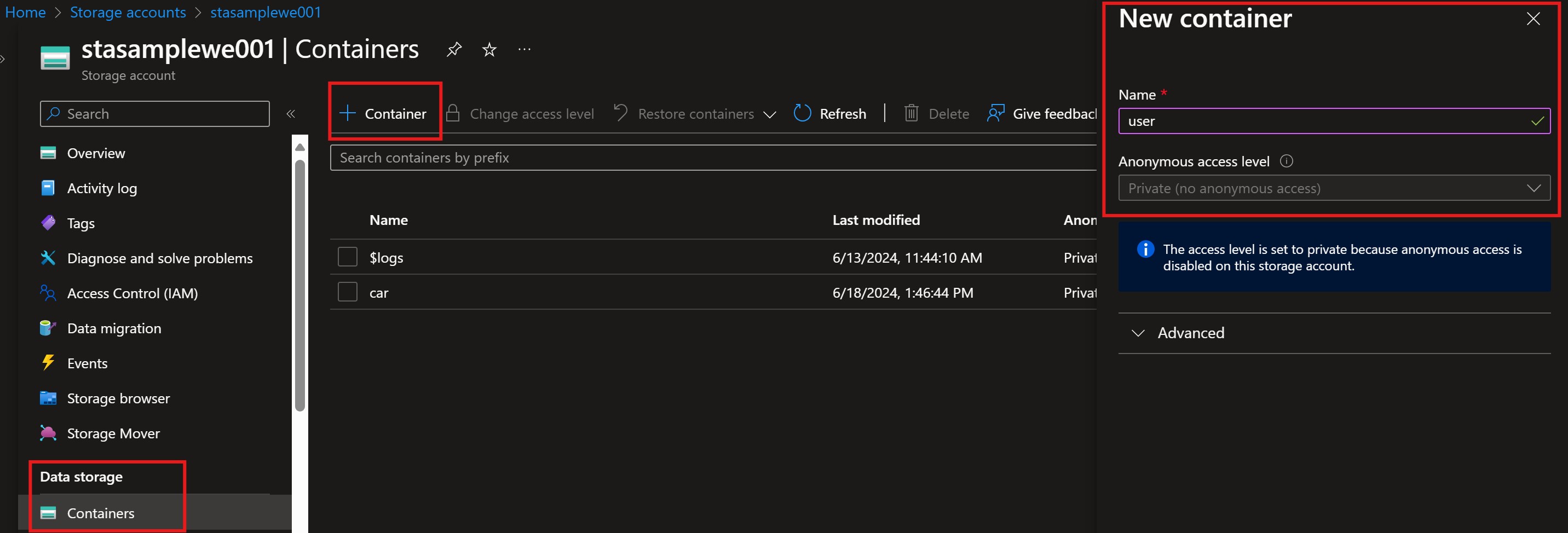 Container creation
Container creationBased on the needs, one container can be created and later on use paths. For example, create container named data_raw and then specify paths /car and /user.
Azure Stream Analytics Job Creation
In the Azure Portal search for Stream Analytics jobs select it and in the upper left corner select + Create
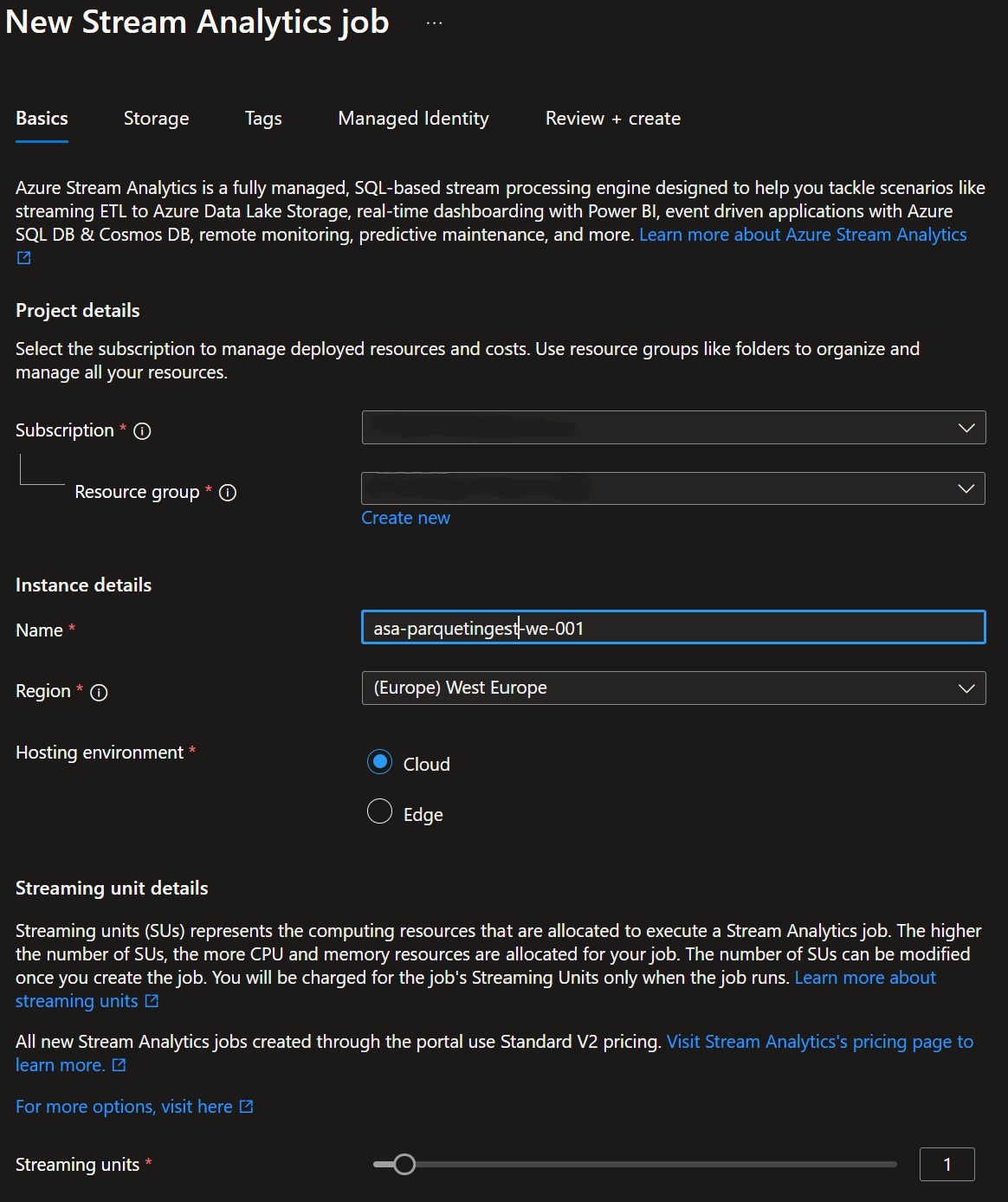 Stream Analytics job creation
Stream Analytics job creation
 Add System Assigned Identity
Add System Assigned Identity
Azure Stream Analytics Job Setup
Once deployment is complete go to resource and you will see your new job.
- Configure Inputs:
Inputs in Azure Stream Analytics Jobs are the entry points for your streaming data. They define where the data is coming from and how it will be ingested into the Stream Analytics Job for processing. Azure Stream Analytics supports a variety of input sources, making it flexible and versatile for different real-time data scenarios.
SelectInputsand in the upper left corner select+Add input. From the dropdown list selectEvent Hub.
Fill in the necessary values. For our example pay attention to the following:- Input Alias: The alias of our input. Will be used in the query later.
- Select the Subscription and the created Event Hub Namespace and Event Hub.
- Create a new Consumer group or select one you have created in previous step.
- Authentication Mode: Select
Managed Identity: System Assigned - Event Serialization Format: JSON
- Event Compression Type: GZIP
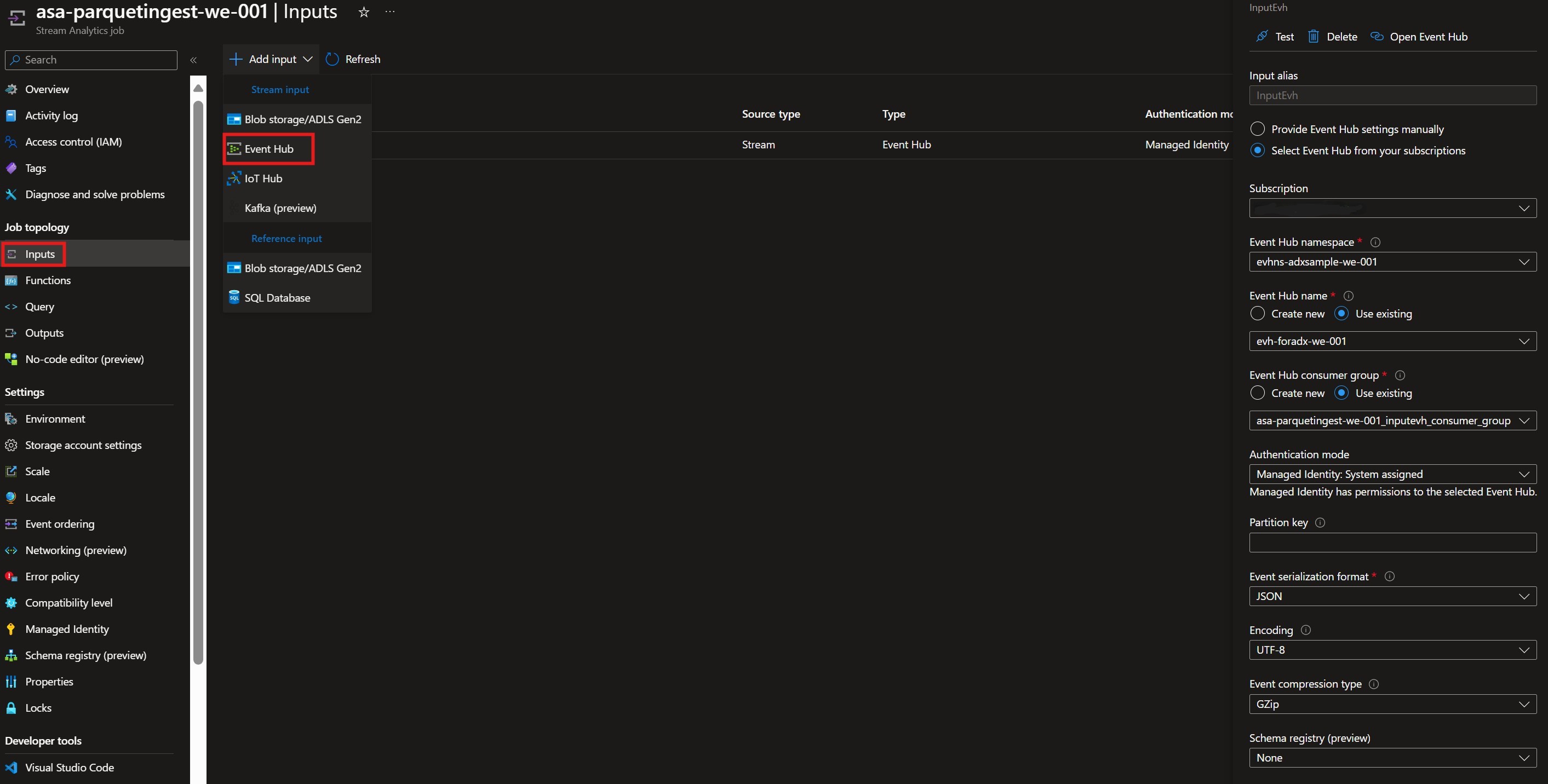 Input creation
Input creation
- Configure Outputs:
Outputs in Azure Stream Analytics Jobs are the destinations where the processed and analyzed data is sent. They define how the results of your Stream Analytics queries are stored, visualized, or further processed. Azure Stream Analytics supports a variety of output destinations, making it flexible and versatile for different real-time data scenarios.
SelectOutputsand in the upper left corner select+Add input. From the dropdown list selectEvent Hub.
Fill in the necessary values. For our example pay attention to the following:- Output Alias: The alias of our output. Will be used in the query later.
- Select the Subscription and the created Storage Account and Container.
- Create a new Consumer group or select one you have created in previous step.
- Authentication Mode: Select
Managed Identity: System Assigned - Write Mode: Select “Once, when all results for the time partition are available. Ensures exactly once delivery (preview)”.
- Path Pattern: Since
Oncewas selected for write mode, Path Pattern becomes mandatory. For our example we will use{date}/{time}.
For our example we will create two (2) outputs one for each container created above.
If one container was created in the storage then here we will change
Path Patternto “user\{date}\{time}” and “car\{date}\{time}”
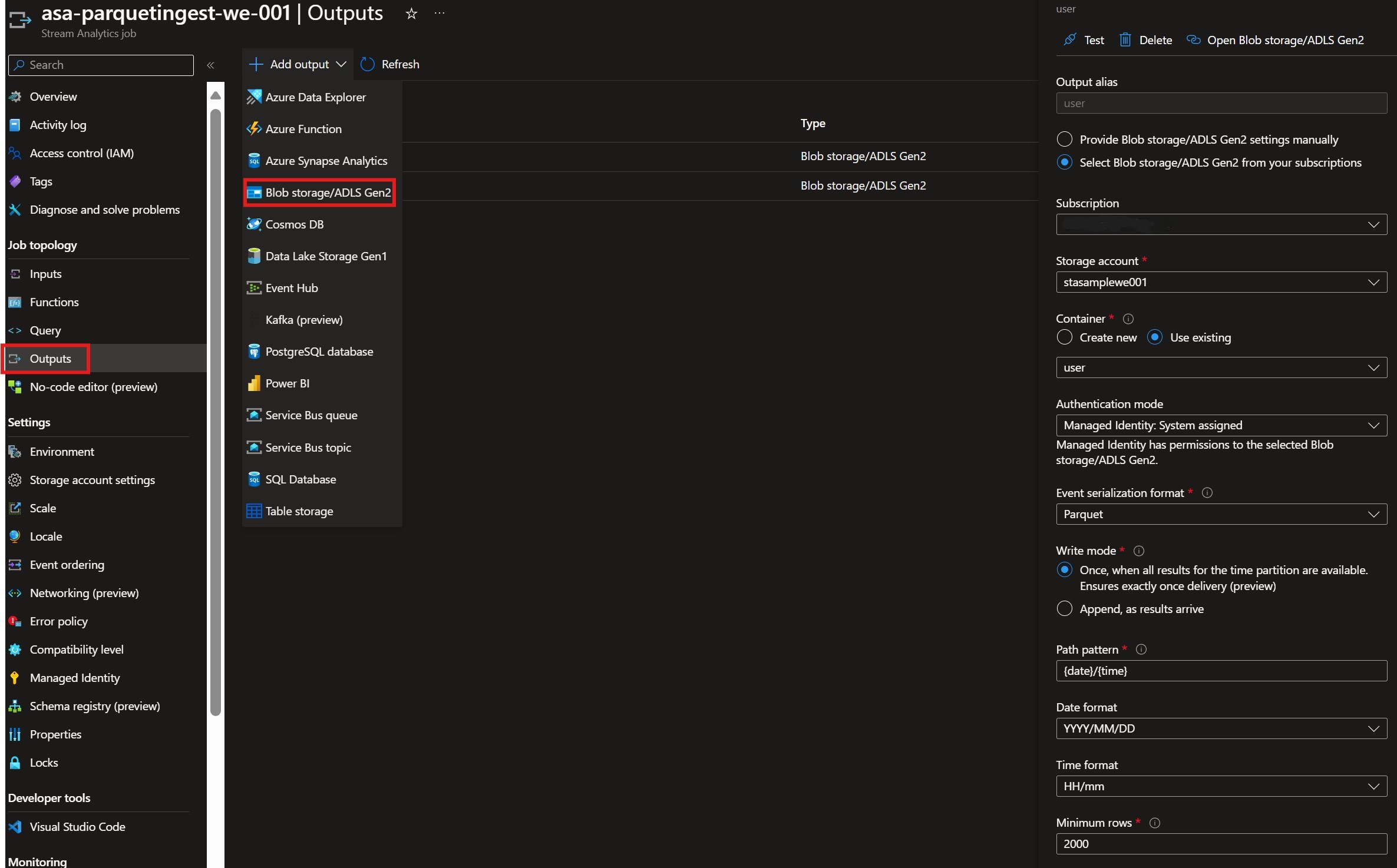 Output creation
Output creation
- Query:
One of the core components of Azure Stream Analytics is the query language, which is based on a subset of SQL. This allows users to write powerful queries to process and analyze streaming data.
In our example we want to route to different container based on our custom input property. To achieve this we will leverage GetMetadataPropertyValue which is a function that allows you to retrieve metadata properties from the input data stream. This function is particularly useful when you need to access system-generated metadata, such as event timestamps, partition keys, or other properties that are not part of the actual data payload.- Common Metadata Properties: EventEnqueuedUtcTime: The UTC time when the event was enqueued.
EventProcessedUtcTime: The UTC time when the event was processed.
PartitionId: The partition ID of the event.
Offset: The offset of the event in the partition.
- Common Metadata Properties: EventEnqueuedUtcTime: The UTC time when the event was enqueued.
Select Query and paste the following:
1
2
3
4
5
6
7
8
WITH StreamData AS (
SELECT *,
GetMetadataPropertyValue(InputEvh, '[User].[Table]') AS TargetTable --Table is our custom property. We use the path [User].[PropertyName] to access it
FROM InputEvh --InputEvh is the alias we set when creating the Input
)
SELECT * INTO [car] FROM StreamData WHERE TargetTable = 'Car' --car is the alias set when creating the output
SELECT * INTO [user] FROM StreamData WHERE TargetTable = 'User' --user is the alias set when creating the output
Start the Console application to send some test data into the Event Hub. In the Query select Refresh to see a sample preview of the data.
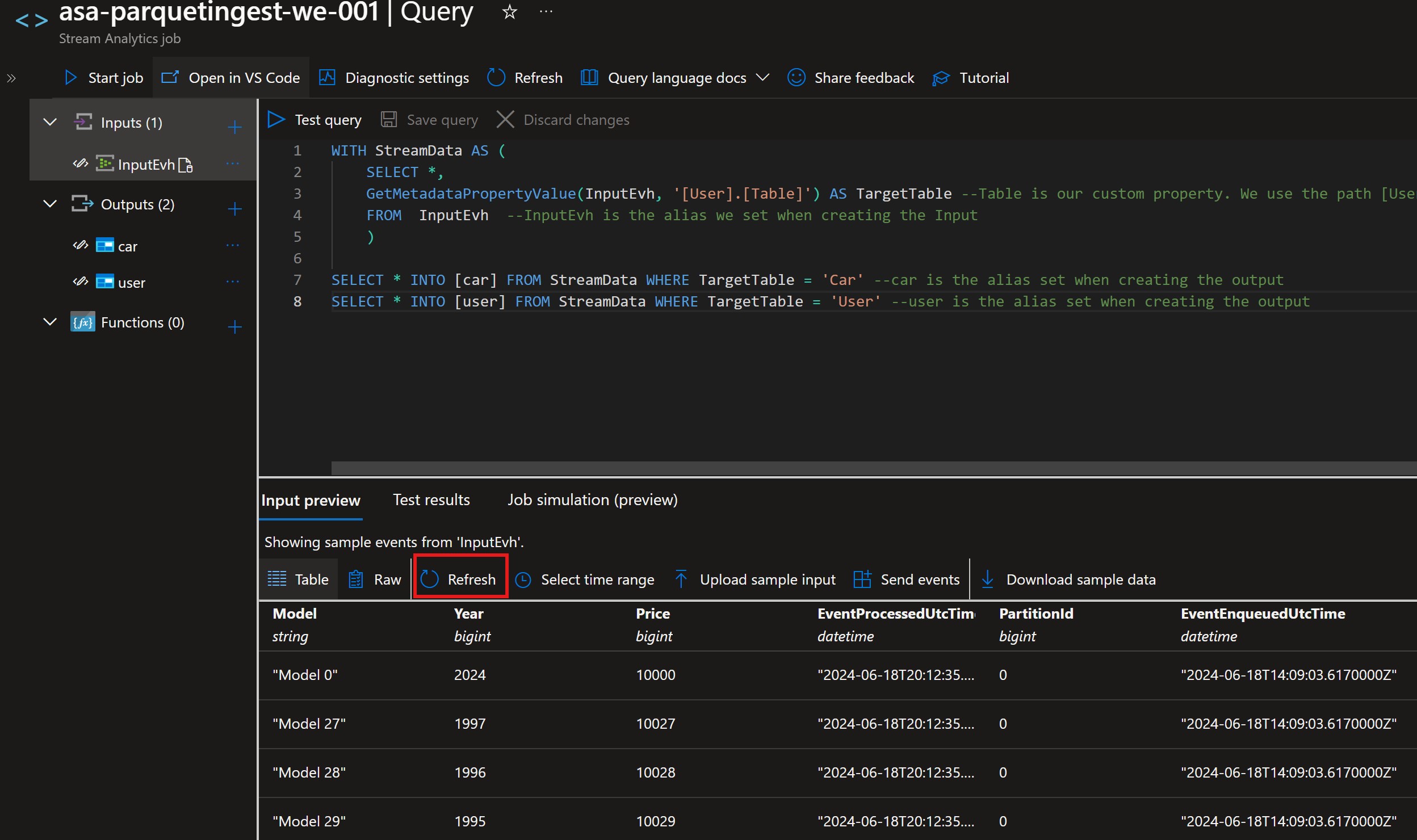 Sample Preview
Sample Preview
- Start the job:
Having everything in place, from the upper left, selectStart Job. Soon, Parquet files will start popping in the containers.
Use ADX to view and query Parquet Data
ADX has introduced the concept of external tables which allow you to query data that resides outside of the ADX database. This can include data stored in various external storage systems such as Azure Blob Storage, Azure Data Lake Storage, and even other databases. By using external tables, you can seamlessly integrate and analyze data from multiple sources without the need to import it into ADX.
Key Benefits of External Tables:
- Data Integration: Easily integrate and query data from different storage systems.
- Cost Efficiency: Avoid the costs associated with data ingestion and storage within ADX.
- Flexibility: Query data in its original location, which is useful for scenarios where data is frequently updated or where you need to maintain a single source of truth.
- Performance: Leverage the powerful query engine of ADX to perform complex analytics on external data.
Create External tables
To create an external table in ADX from the Azure portal, navigate to your cluster, select your Database, right click and select Create external table.
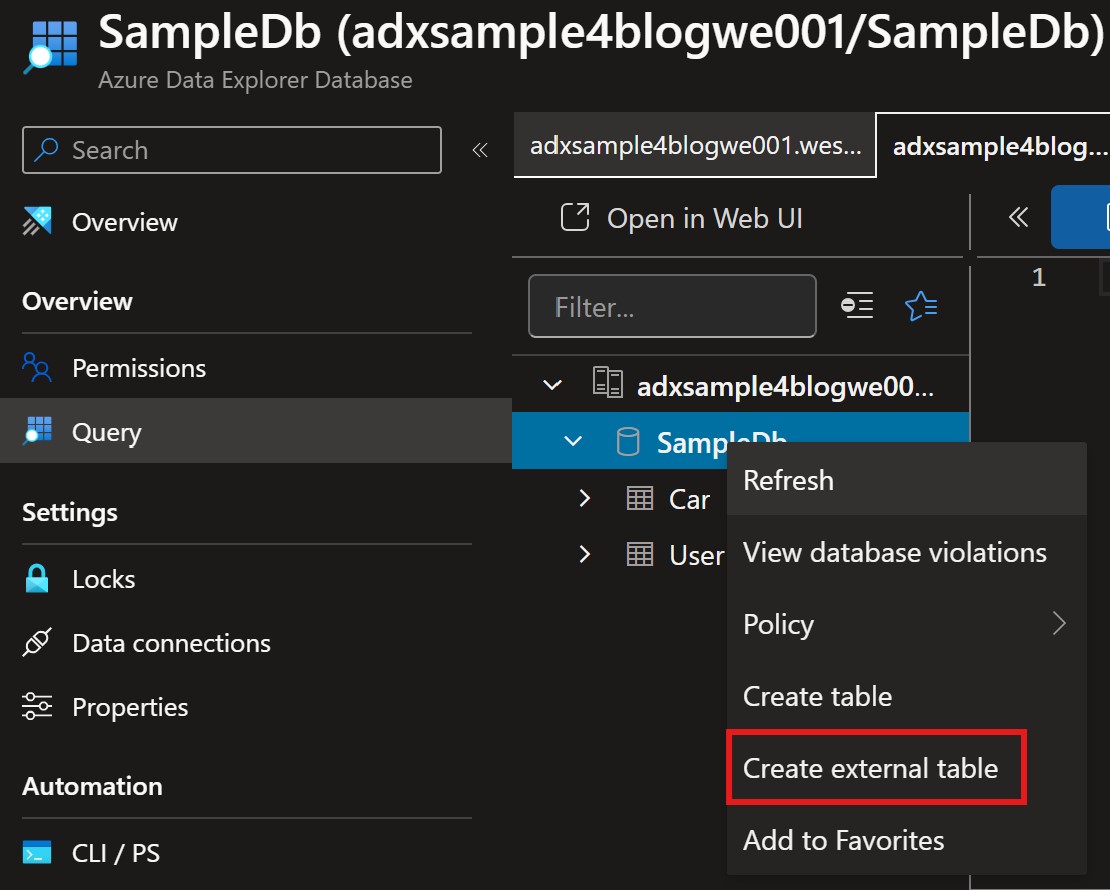 External table creation
External table creation
When creating the external table for first time you will need to grant the
Storage Blob Data Readerrole assignment.
Select the container that corresponds to the table we want to create.
File filter can be used to specify specific files. For our example if the approach with one container with paths was selected, then we can specify the paths (i.e. car/, /user).
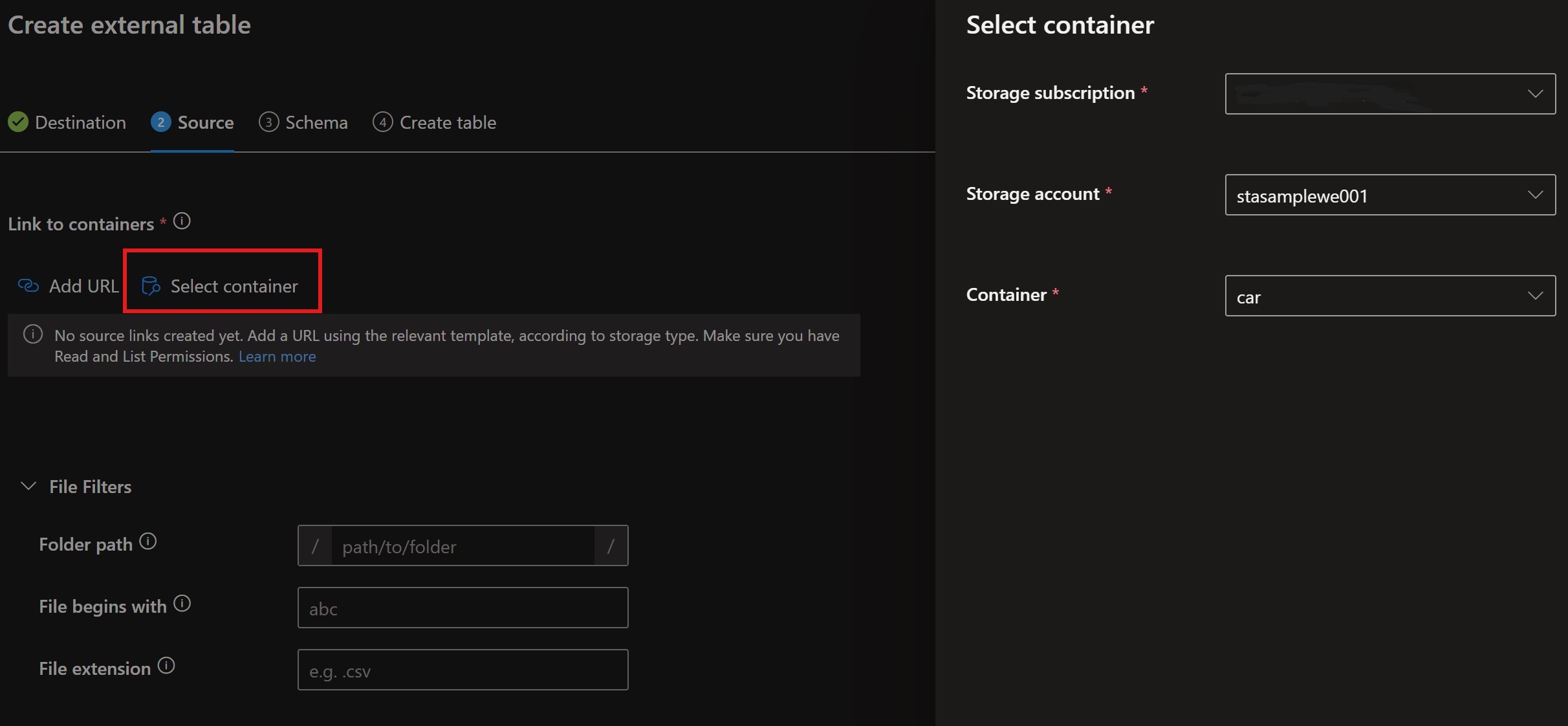 External table container selection
External table container selection
Table schema will be determined automatically. It can be altered according to our needs (e.g. change data types or delete specific columns).
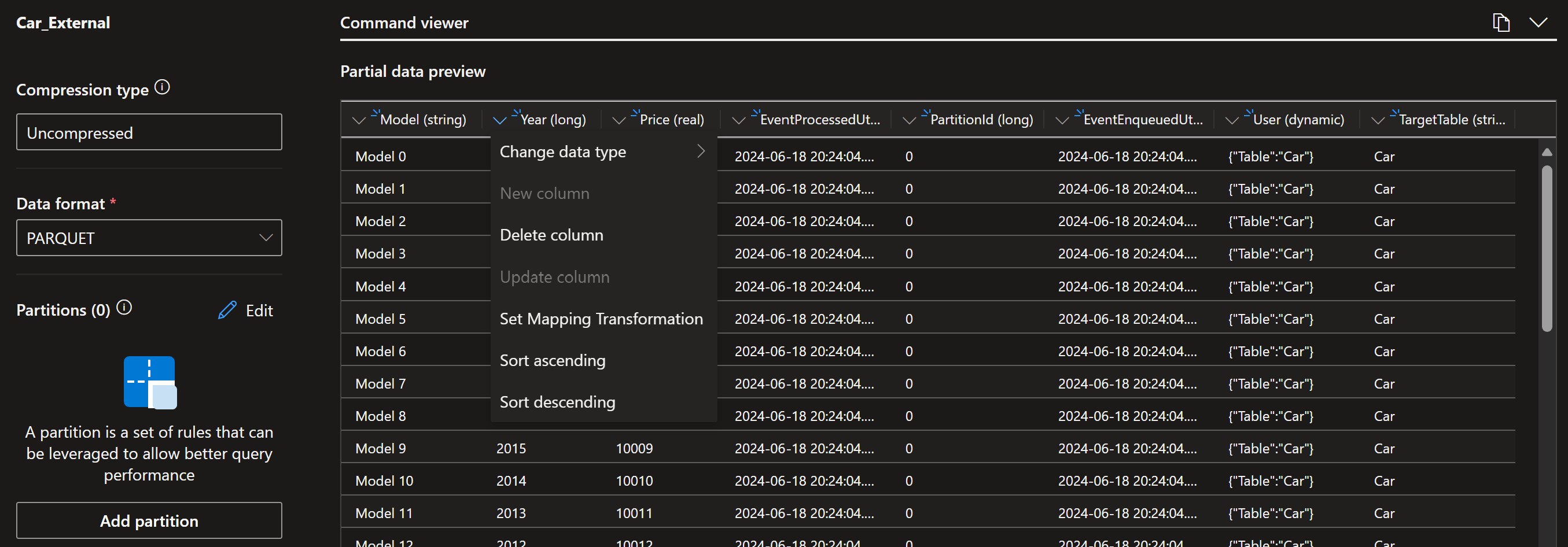 External table schema definition
External table schema definition
Once done, tables will be visible under the External Tables folder. We can query them using the external_table("TableName") command.
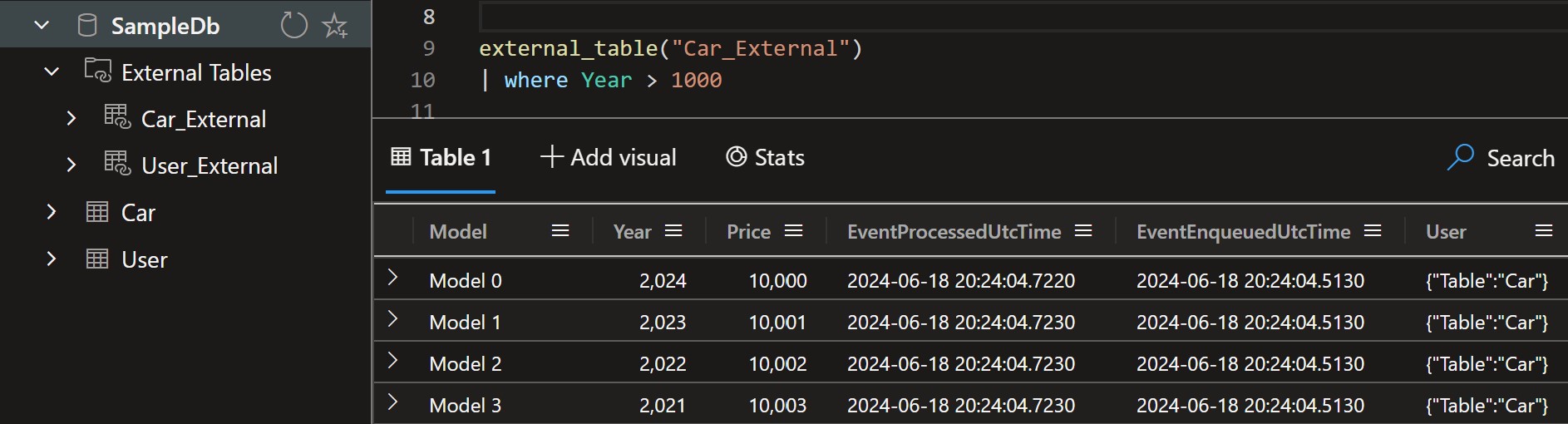 External table query
External table query
Conclusion
By leveraging Azure Event Hub, Azure Stream Analytics, Parquet format, Azure Data Lake Storage, and Azure Data Explorer, you can easily create a robust and efficient pipeline (with zero code) that meets your real-time data processing needs.
This architecture not only ensures scalability and performance but also provides flexibility in querying and analyzing data. Whether you’re monitoring IoT devices, analyzing financial transactions, or processing social media feeds, this pipeline can be adapted to suit various use cases.